Step-by-Step Guide to Creating an AWS RDS Database Instance

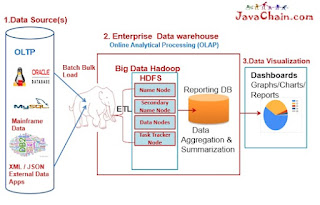
Amazon Relational Database Service (AWS RDS) makes it easy to set up, operate, and scale a relational database in the cloud. Instead of managing servers, patching OS, and handling backups manually, AWS RDS takes care of the heavy lifting so you can focus on building applications and data pipelines. In this blog, we’ll walk through how to create an AWS RDS instance , key configuration choices, and best practices you should follow in real-world projects. What is AWS RDS? AWS RDS is a managed database service that supports popular relational engines such as: Amazon Aurora (MySQL / PostgreSQL compatible) MySQL PostgreSQL MariaDB Oracle SQL Server With RDS, AWS manages: Database provisioning Automated backups Software patching High availability (Multi-AZ) Monitoring and scaling Prerequisites Before creating an RDS instance, make sure you have: An active AWS account Proper IAM permissions (RDS, EC2, VPC) A basic understanding of: ...